Курс Scalable
Machine Learning. Hadoop, Apache Spark, Python, ML -- вот это
всё.
Продолжаю
конспектировать пройденный курс. Неделя
4.
В прошлый
раз было про One-hot-encoding для трансформации
фич в числа и про хеширование как средство
снижения размерности датасета.
Пришло время
потрогать пройденные темы на практике.
Лабораторка.
CTR PREDICTION
PIPELINE LAB PREVIEW
In this segment, we'll
provide an overview
of the click-through
rate prediction pipeline
that you'll be working
on in this week's Spark coding lab.
The goal of the lab is
to implement a click-through rate
prediction pipeline
using various techniques that we've
discussed in this
week's lecture
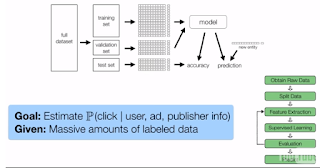

The raw data consists
of a subset of a data
from a Kaggle
competition sponsored by Criteo.
This data includes 39
features describing users, ads,
and publishers.
Many of these features
contain a large number of categories
You'll next need to
extract features
to feed into a
supervised learning model.
And feature
extraction is the main focus of this lab.
You'll create OHE
features, as well as hashed features,
and store these
features using a sparse representation.
Экстрагировать
фичи это не так страшно как кажется.
Банальная трансформация. Типа текстовых
данных в числа; комбинированные фичи,
и т. д.
Given a set of
features, either OHE or hashed features,
you will use MLlib to
train logistic regression models.
You will then perform
Hyperparameter
tuning to search for a
good regularization parameter,
evaluating the results
via log loss,
and visualizing the
results of your grid search.
Понятно вроде.
ОК, забираем
нотебук
Запускаем
виртуалку
valik@snafu:~$ pushd ~/sparkvagrant/ valik@snafu:~/sparkvagrant$ vagrant up
И вперед: http://localhost:8001/tree
На Гитхабе
этот нотебук
Программа
действий:
-
Part 1: Featurize categorical data using one-hot-encoding (OHE)
-
Part 2: Construct an OHE dictionary
-
Part 3: Parse CTR data and generate OHE features: Visualization 1: Feature frequency
-
Part 4: CTR prediction and logloss evaluation: Visualization 2: ROC curve
-
Part 5: Reduce feature dimension via feature hashing: Visualization 3: Hyperparameter heat map
Для справки
Part 1: Featurize
categorical data using one-hot-encoding (OHE)
(1a) One-hot-encoding
Сначала создадим
словарь OHE вручную, для разминки возьмем
датасет из трех записей про трех животных.
# Data for manual OHE
# Note: the first data point does not include any value for the optional third feature
sampleOne = [(0, 'mouse'), (1, 'black')]
sampleTwo = [(0, 'cat'), (1, 'tabby'), (2, 'mouse')]
sampleThree = [(0, 'bear'), (1, 'black'), (2, 'salmon')]
sampleDataRDD = sc.parallelize([sampleOne, sampleTwo, sampleThree])
sampleOHEDictManual = {}
sampleOHEDictManual[(0,'bear')] = 0
sampleOHEDictManual[(0,'cat')] = 1
sampleOHEDictManual[(0,'mouse')] = 2
sampleOHEDictManual[(1,'black')] = 3
sampleOHEDictManual[(1,'tabby')] = 4
sampleOHEDictManual[(2,'mouse')] = 5
sampleOHEDictManual[(2,'salmon')] = 6
|
Всего семь
категорий.
(1b) Sparse vectors
https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.linalg.SparseVector
Надо
потренироваться в создании sparse векторов.
Пока вручную.
import numpy as np from pyspark.mllib.linalg import SparseVector # TODO: Replace <FILL IN> with appropriate code aDense = np.array([0., 3., 0., 4.]) aSparse = SparseVector(len(aDense), enumerate(aDense)) bDense = np.array([0., 0., 0., 1.]) bSparse = SparseVector(len(bDense), enumerate(bDense)) w = np.array([0.4, 3.1, -1.4, -.5]) print aDense.dot(w) print aSparse.dot(w) print bDense.dot(w) print bSparse.dot(w) |
Что характерно,
несмотря на то, что такое решение
удовлетворяет условиям теста (умножение
дает одинаковые результаты), решение
неправильное.
Правильно
будет так:
aDense = np.array([0., 3., 0., 4.])
aSparse = SparseVector(len(aDense), {1: 3., 3: 4.})
bDense = np.array([0., 0., 0., 1.])
bSparse = SparseVector(len(bDense), [(3, 1.)])
Почему? Потому,
что гладиолус. Смотри определение
SparseVector.
(1c) OHE features as
sparse vectors
Теперь, когда
идея понятна, создадим SparseVector-ы для
игрушечного датасета с животными.
Если идея
непонятна, то вот: имеем семь категорий,
значит вектор будет длинной 7. Изначально
весь в нулях. Для каждой записи берем
такой вектор и ставим единички по номерам
из словаря, ключ в словаре – исходная
фича записи.
Пример:
(животное, мышка) в словаре дает 2. Значит
в SparseVector ставим единичку в позиции 2
(считая с 0).
# sampleOHEDictManual[(0,'bear')] = 0
# sampleOHEDictManual[(0,'cat')] = 1
# sampleOHEDictManual[(0,'mouse')] = 2
# sampleOHEDictManual[(1,'black')] = 3
# sampleOHEDictManual[(1,'tabby')] = 4
# sampleOHEDictManual[(2,'mouse')] = 5
# sampleOHEDictManual[(2,'salmon')] = 6
# sampleOne = [(0, 'mouse'), (1, 'black')] = 2, 3
sampleOneOHEFeatManual = SparseVector(7, {2: 1.0, 3: 1.0})
# sampleTwo = [(0, 'cat'), (1, 'tabby'), (2, 'mouse')] = 1, 4, 5
sampleTwoOHEFeatManual = SparseVector(7, {1: 1.0, 4: 1.0, 5: 1.0})
# sampleThree = [(0, 'bear'), (1, 'black'), (2, 'salmon')] = 0, 3, 6
sampleThreeOHEFeatManual = SparseVector(7, {0: 1.0, 3: 1.0, 6: 1.0})
|
Несложно,
правда? А я довольно долго колупался,
пока не сообразил, как надо правильно
записывать SparseVector-ы.
(1d) Define a OHE
function
Напишем функцию,
которая возвращает нам SparseVector для записи
исходного датасета.
def oneHotEncoding(rawFeats, OHEDict, numOHEFeats):
"""Produce a one-hot-encoding from a list of features and an OHE dictionary.
Note:
You should ensure that the indices used to create a SparseVector are sorted.
Args:
rawFeats (list of (int, str)): The features corresponding to a single observation. Each
feature consists of a tuple of featureID and the feature's value.
(e.g. sampleOne) sampleOne = [(0, 'mouse'), (1, 'black')]
OHEDict (dict): A mapping of (featureID, value) to unique integer.
OHE Dictionary example:
sampleOHEDictManual[(0,'bear')] = 0
...
sampleOHEDictManual[(1,'black')] = 3
...
sampleOHEDictManual[(2,'salmon')] = 6
numOHEFeats (int): The total number of unique OHE features (combinations of featureID and
value).
Returns:
SparseVector: A SparseVector of length numOHEFeats with indicies equal to the unique
identifiers for the (featureID, value) combinations that occur in the observation and
with values equal to 1.0.
e.g. sampleOneOHEFeatManual = SparseVector(7, {2: 1.0, 3: 1.0})
"""
spDict = {}
для каждой фичи:
key = значение из словаря ОХЕ
if key is not None:
spDict[key] = 1.0
res = SparseVector(numOHEFeats, spDict)
return res
# Calculate the number of features in sampleOHEDictManual
numSampleOHEFeats = len(sampleOHEDictManual)
# Run oneHotEnoding on sampleOne
sampleOneOHEFeat = oneHotEncoding(sampleOne, sampleOHEDictManual, numSampleOHEFeats)
|
(1e) Apply OHE to a
dataset
Ну, тут все
элементарно, применить функцию к
исходному датасету, получив закодированный
датасет, готовый к скармливанию в
logistic regression.
sampleOHEData = sampleDataRDD.map(lambda x: oneHotEncoding(x, sampleOHEDictManual, numSampleOHEFeats)) print sampleOHEData.collect()
[SparseVector(7, {2: 1.0, 3: 1.0}), SparseVector(7, {1: 1.0, 4: 1.0,
5: 1.0}), SparseVector(7, {0: 1.0, 3: 1.0, 6: 1.0})]
Part 2: Construct an
OHE dictionary
(2a) Pair RDD of
(featureID, category)
Надо
автоматизировать создание словаря. А
то он у нас был ручками записан.
Для начала
создадим RDD с уникальными значениями
фич из исходного списка списков.
create an RDD of
distinct (featureID, category) tuples
# sampleOne = [(0, 'mouse'), (1, 'black')]
# sampleTwo = [(0, 'cat'), (1, 'tabby'), (2, 'mouse')]
# sampleThree = [(0, 'bear'), (1, 'black'), (2, 'salmon')]
# sampleDataRDD = sc.parallelize([sampleOne, sampleTwo, sampleThree])
sampleDistinctFeats = (sampleDataRDD
.плоский список(lambda x: x)
.выкинуть дубли())
|
(2b) OHE Dictionary
from distinct features
Вот теперь
можно сгенерировать словарь, сопоставив
уникальные категории номерам по порядку.
sampleOHEDict = (sampleDistinctFeats
.сгенерить индексы()
.собрать словарь())
print sampleOHEDict
|
{(2, 'mouse'): 0, (0,
'cat'): 1, (0, 'bear'): 2, (2, 'salmon'): 3, (1, 'tabby'): 4, (1,
'black'): 5, (0, 'mouse'): 6}
(2c) Automated creation
of an OHE dictionary
Собираем лего:
напишем функцию, которая вернет нам
словарь для исходного датасета (исходный
датасет это список списков туплей).
def createOneHotDict(inputData):
"""Creates a one-hot-encoder dictionary based on the input data.
Args:
inputData (RDD of lists of (int, str)): An RDD of observations where each observation is
made up of a list of (featureID, value) tuples.
Returns:
dict: A dictionary where the keys are (featureID, value) tuples and map to values that are
unique integers.
"""
distinctFeats = (inputData
.плоский список(lambda x: x)
.выкинуть дубли())
res = (distinctFeats
.сгенерить индексы()
.собрать словарь())
return res
sampleOHEDictAuto = createOneHotDict(sampleDataRDD)
print sampleOHEDictAuto
|
{(2, 'mouse'): 0, (0,
'cat'): 1, (0, 'bear'): 2, (2, 'salmon'): 3, (1, 'tabby'): 4, (1,
'black'): 5, (0, 'mouse'): 6}
На сегодня
хватит, продолжим завтра.
Следующий
номер программы:
Part 3: Parse CTR
data and generate OHE features
Visualization 1:
Feature frequency
original post http://vasnake.blogspot.com/2015/11/week-4-lab-4.html
Комментариев нет:
Отправить комментарий